data2vec 论文阅读
概述
和Bert等预训练模型的本质区别在于:Bert在原始文本上mask,而该模型在latent representation上进行预测。文章认为所有模态在latent representation上都是一些稠密向量,所以训练的方法相同。
模型细节
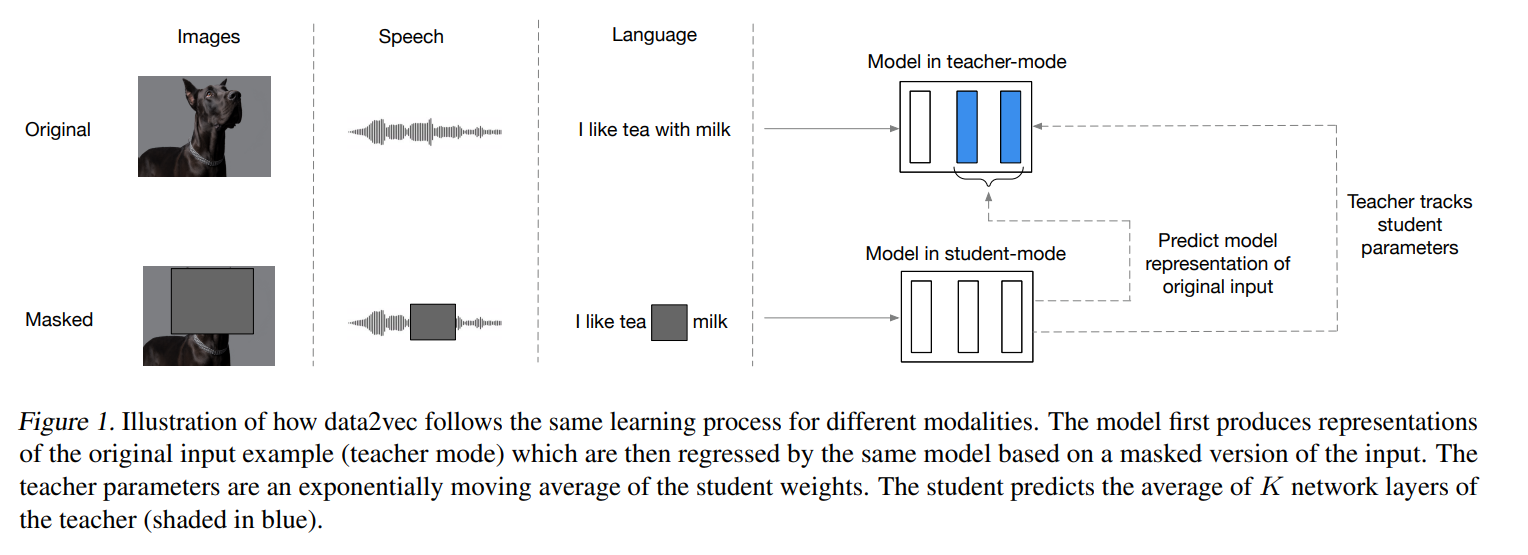
所有模态的数据在encoder之后。然后复制两份,一份mask之后通过student model,只在mask的地方产生输出。一份不mask,给teacher model直接学习上下文表示,然后让两者的输出对齐。
Encoder 细节
encoder部分并没有将不同模态统一。
- 视觉:参考ViT
- 语音: 一个多层 1-D 卷积层, 16 kHz waveform to 50 Hz representations
- 文本:token embedding
Masking 细节
mask也不是统一的。
- 视觉:block-wise masking strategy
- 语音:mask spans of latent speech representations
- 文本:tokens
student model & teacher model细节
都是普通Transformer。
其中,teacher model的参数遵循以下公式:
\[ \Delta \leftarrow \tau \Delta + (1 - \tau) \theta \]
其中 \(\Delta\) 是teacher model的参数, \(\theta\) 是student model 的参数。 \(\tau\) 是缓慢增加的。
学生模型的训练目标是:
\[ y_t = \frac{1}{K} \sum_{l=L-K+1}^{L} \hat{a}_{l,t} \]
其中, \(\hat{a}_{l,t}\) 是teacher model经过归一化的第\(l\)个块在时间步 \(t\) 的输出,\(K\)是前\(K\)个块的数量,\(L\)是总块数。
data2vec 论文阅读
http://example.com/2025/03/10/data2vec-论文阅读/