unispeech 论文阅读
概述
利用L、M、N三个数据集(定义见下)。
在L、M上预训练模型。
冻结特征提取器,并在N上对Transformer部分进行微调。
定义
L:大规模、有标签的high-resource语种数据集
M:大规模、无标签的low-resource语种数据集
N:小规模、有标签的low-resource语种数据集
模型结构
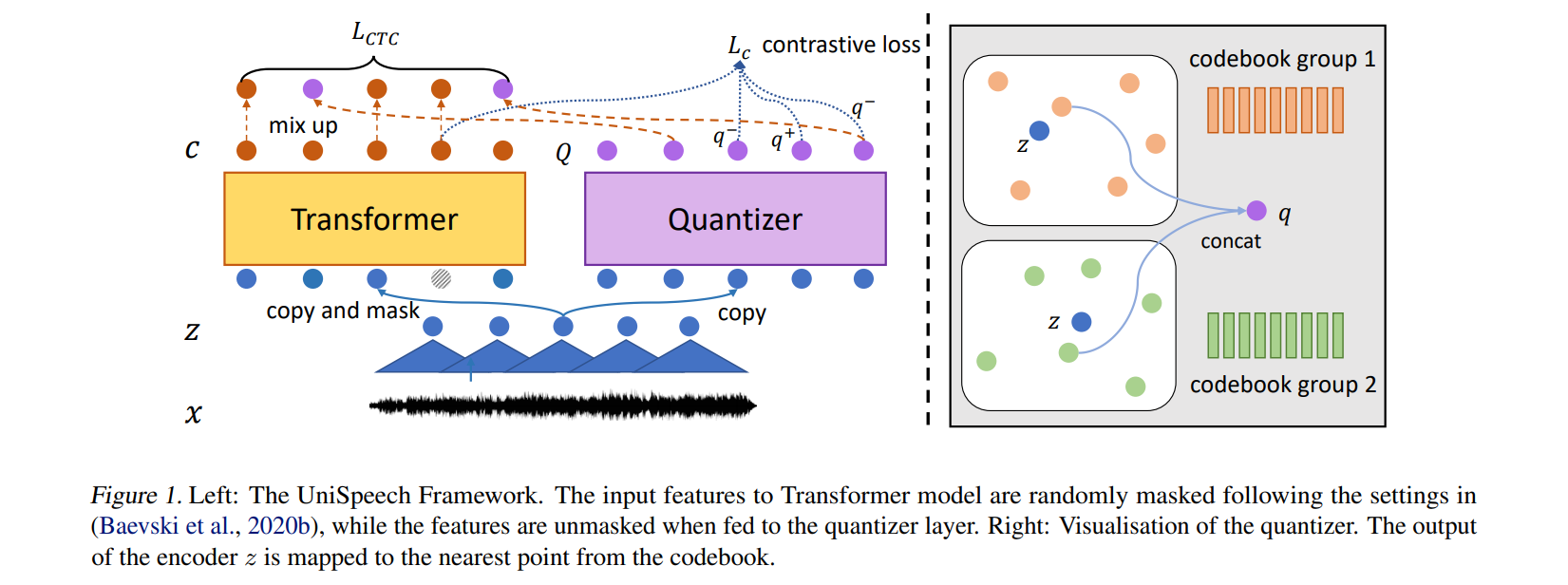
使用multitask学习方法。
- 目标1:sequence-level CTC loss
\[ L_{\text{ctc}} = - \log p_{\text{ctc}}(y|x) = \sum_{\pi \in \Phi_{x,y}} p(\pi | c_1, \dots, c_T) \]
- 目标2:基于wav2vec2.0,在masked contextual representations和discrete latent representations之间的对比学习
对比学习loss:
\[ L_c = - \log \frac{\exp(\text{sim}(c_t, q_t) / \kappa)}{\sum_{q' \sim Q_t} \exp(\text{sim}(c_t, q') / \kappa)} \]
codebook diversity loss:
\[ \quad L_d = \frac{1}{GV} \sum_{g=1}^{G} \sum_{v=1}^{V} \bar{p}_{g,v} \log \bar{p}_{g,v} \]
\[ L_{\text{self}} = L_c + 0.1 \times L_d \]
最终预训练的loss:
\[ \quad L = \sum_{(x,y) \in L} \left( \alpha L_{\text{ctc}} + (1 - \alpha) L_{\text{self}} \right) + \sum_{(x) \in M} L_{\text{self}} \]
问题
- 训练时是混合训练吗?
- 为什么要训练码本?如果码本和Transformer结构要尽量相似的话
unispeech 论文阅读
http://example.com/2025/02/27/unispeech-论文阅读/