VietASR论文阅读
概述
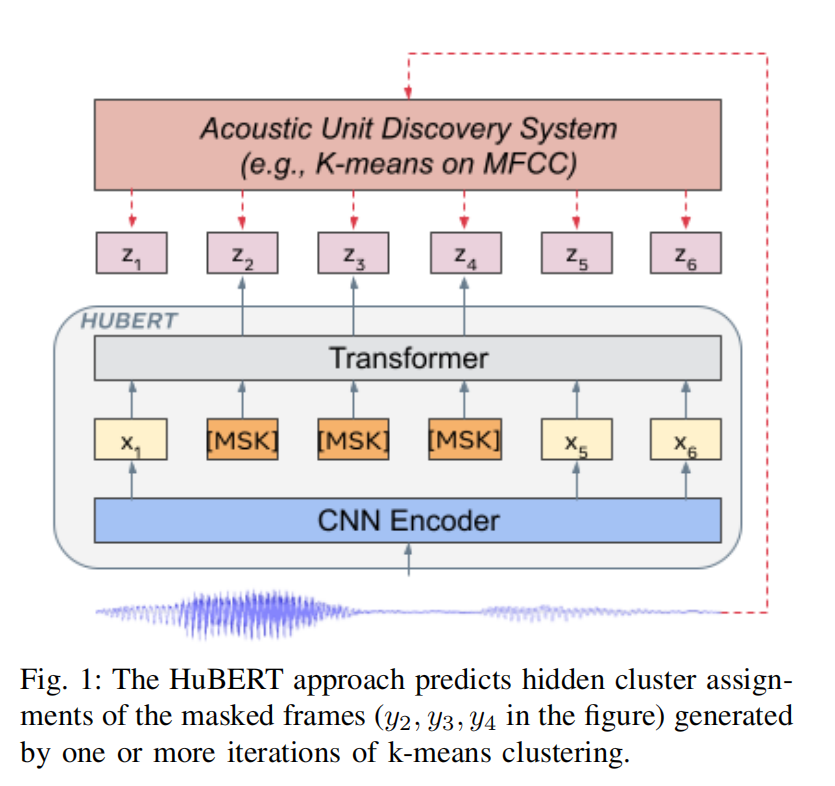
VietASR是一个针对小语种的ASR Pipeline,结合了HuBert和Zipformer,本质是HuBert对ASR的适配。
对HuBert的改动
- VietASR使用Fbank直接进行掩码,替代音频+CNN。
- 修改损失函数
回顾,HuBert中
\[ L_m(f;X,M,Z)= \sum_{t\in M}logp_f(z_t|\tilde{X},t) \]
\[ p_f^{(k)}(c | \tilde{X}, t) = \frac{\exp(\text{sim}(A^{(k)} o_t, e_c)/\tau )}{\sum\limits_{c' =1}^{C} \exp(\text{sim}(A^{(k)} o_t, e_{c'})/\tau )} \]
一些符号说明
$ X = [x_1,..,x_T] $ 为T个frame的语音输入。
$ Z=[z_1,..,z_T] 为 $Acoustic Unit Discovery模型输出的hidden units。
\(z_t \in [C]\) 是一个C-class的变量,为语音的离散表示。
\(h\)是一个非监督的聚类模型,如k-means on MFCC。
\(f\)是HuBert预训练模型。
\(A^{(k)}\) 是第k个聚类的投影矩阵,乘以 \(o_t\) 之后变成C-class的离散变量。
\([o_1, ..., o_T]\) 为Bert的输出。
\(e_c\) 是 \(c\) 的嵌入向量。
\(sim(·,·)\) 是两个向量之间的余弦相似度。
\(\tau\) 是logit scaling factor。
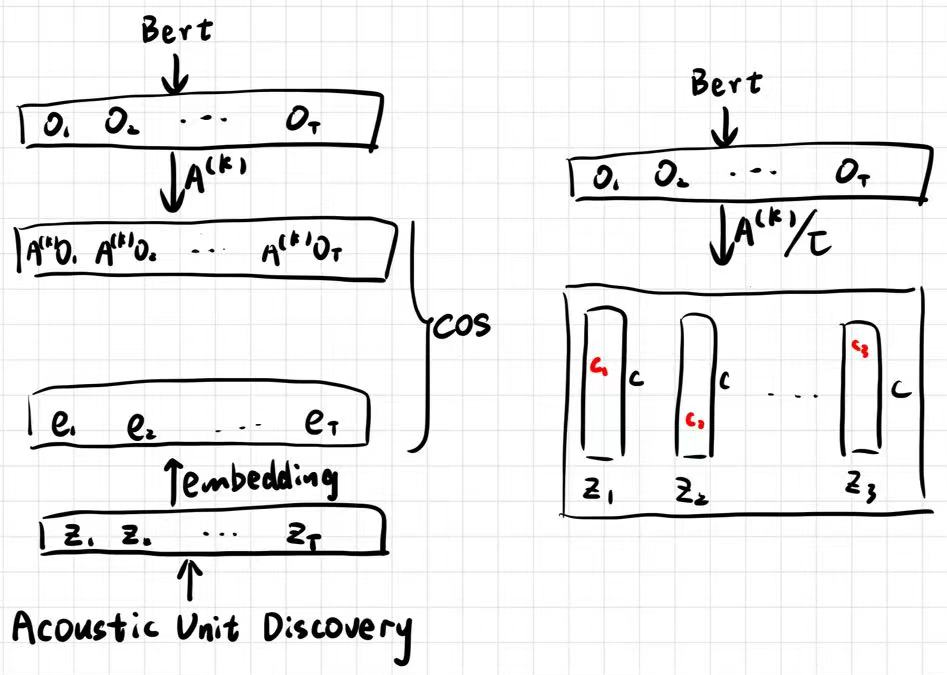
而VietASR修改了损失函数,从余弦相似度变为(论文中这里 \(f\) 是loss函数。\(z\)也不是类别,而是Bert预测的所有类别的softmax概率。这两个记号和HuBert中不同):
\[ f(\tilde{X}, c) = - \sum_{t \in \text{masked}} \log \frac{\exp(z_{tc_t})}{\sum_{i=1}^C \exp(z_{t,i})} \tag{1} \]
\[ o = \text{encoder}(\tilde{X}) = (o_1, o_2, \dots, o_T) \tag{2} \]
\[ z_t = A o_t / \tau = (z_{t1}, z_{t2}, \dots, z_{tC}) \tag{3} \]
其中,\(X_e\) 表示带掩码的输入,\(c\) 表示簇(cluster)标签,\(A\) 表示投影矩阵,\(\tau\) 为温度参数。
这种简化方式来自于李宏毅组的工作MELHUBERT: A SIMPLIFIED HUBERT ON MEL SPECTROGRAMS,优化了cos带来的大量运算,其本质是使用生成学习而非原来的对比学习,示意图如下。左侧为HuBert原始结构,右侧为改进后的结构:
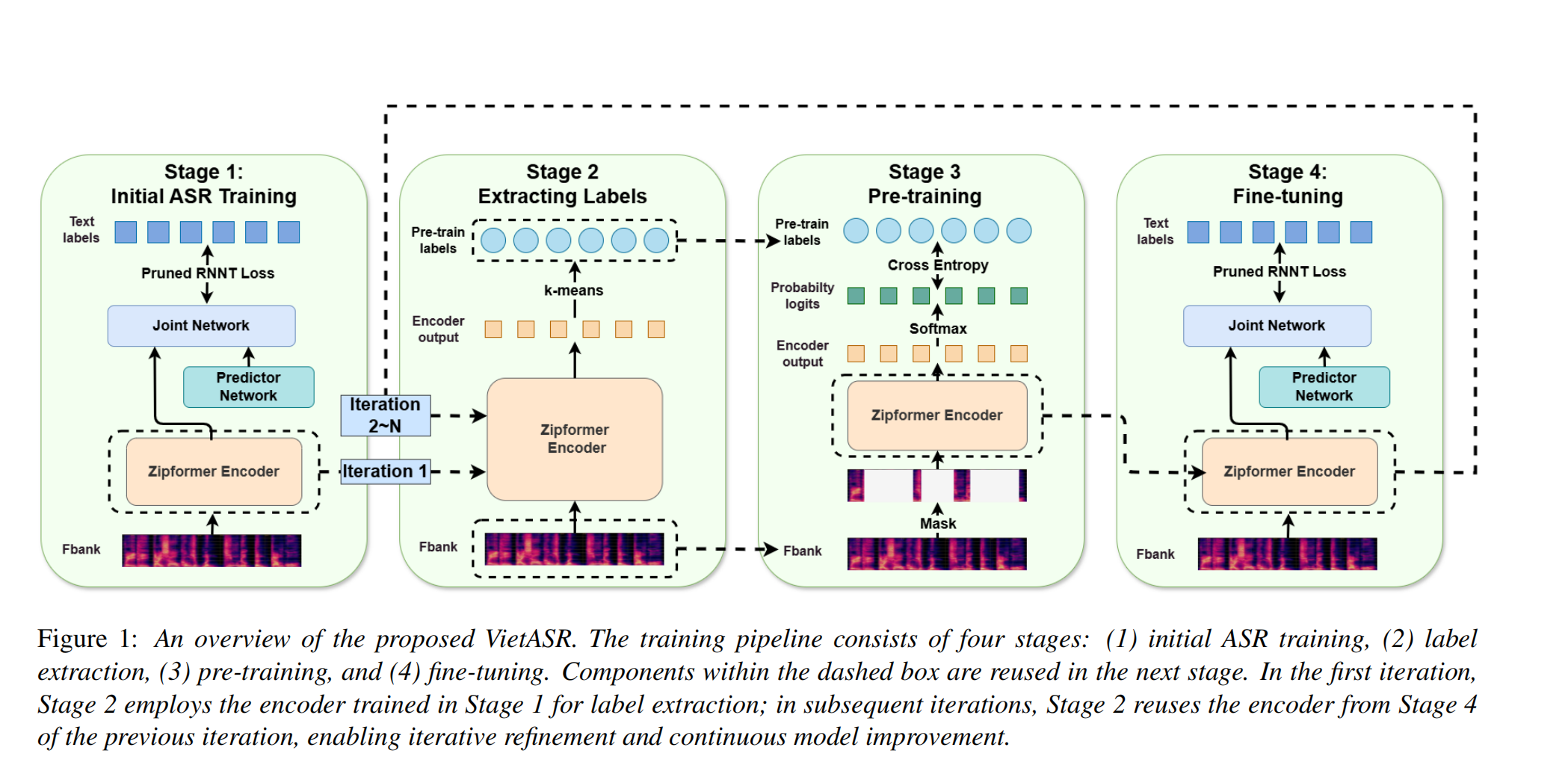
Pipeline
在小规模有监督数据上训练一个Zipformer ASR模型,使用RNN-T loss。
对训练好的Zipformer的encoder输出应用k-means,作为HuBert标签。
使用上面的标签进行HuBert训练,采用cross-entropy优化。
使用pruned RNN-T loss对预训练的encoder微调。