语音基础知识
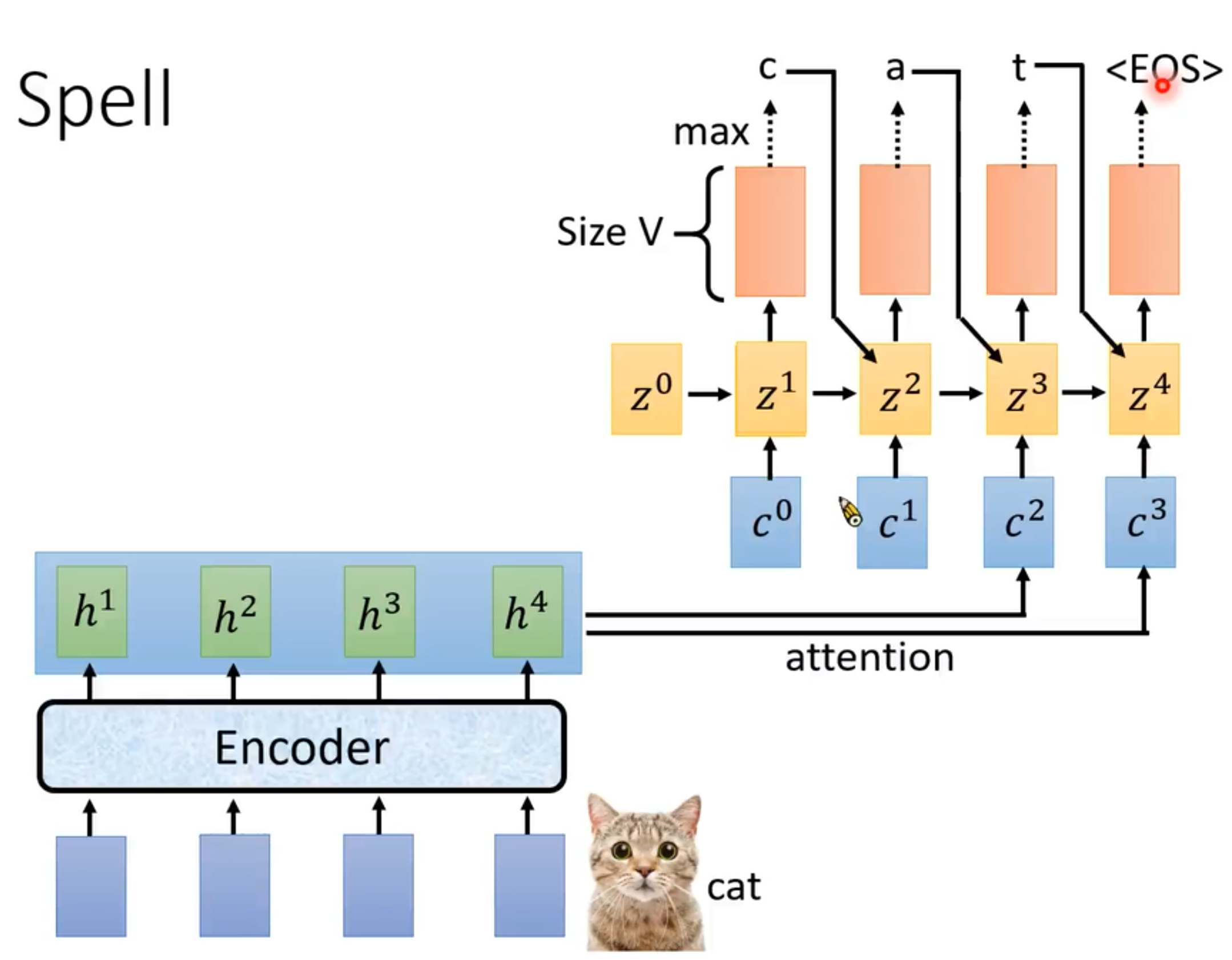
LAS
Listen: Encoder Attend: Attention Spell:Decoder 典型的seq2seq with attention
Encoder
- 输入acoustic features, 输出提取出的特征
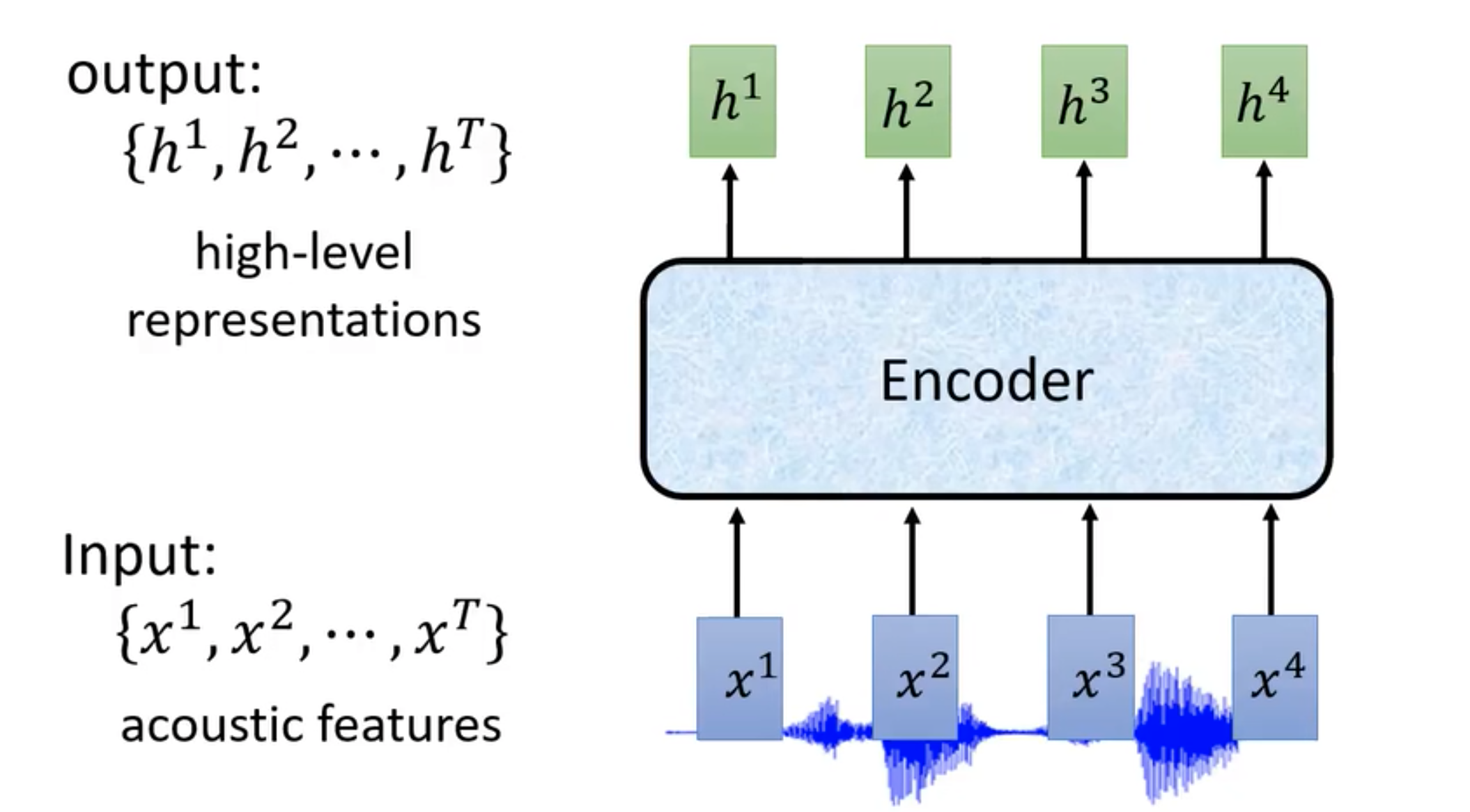
Encoder可以是RNN+CNN,也可以是self-attention
可以做down sampling 降低运算量
- 方法:空洞卷积(CNN)、truncated attention
Attention
Decoder
可以采用RNN。每一个token输出一个分布,维度=vocabulary_size
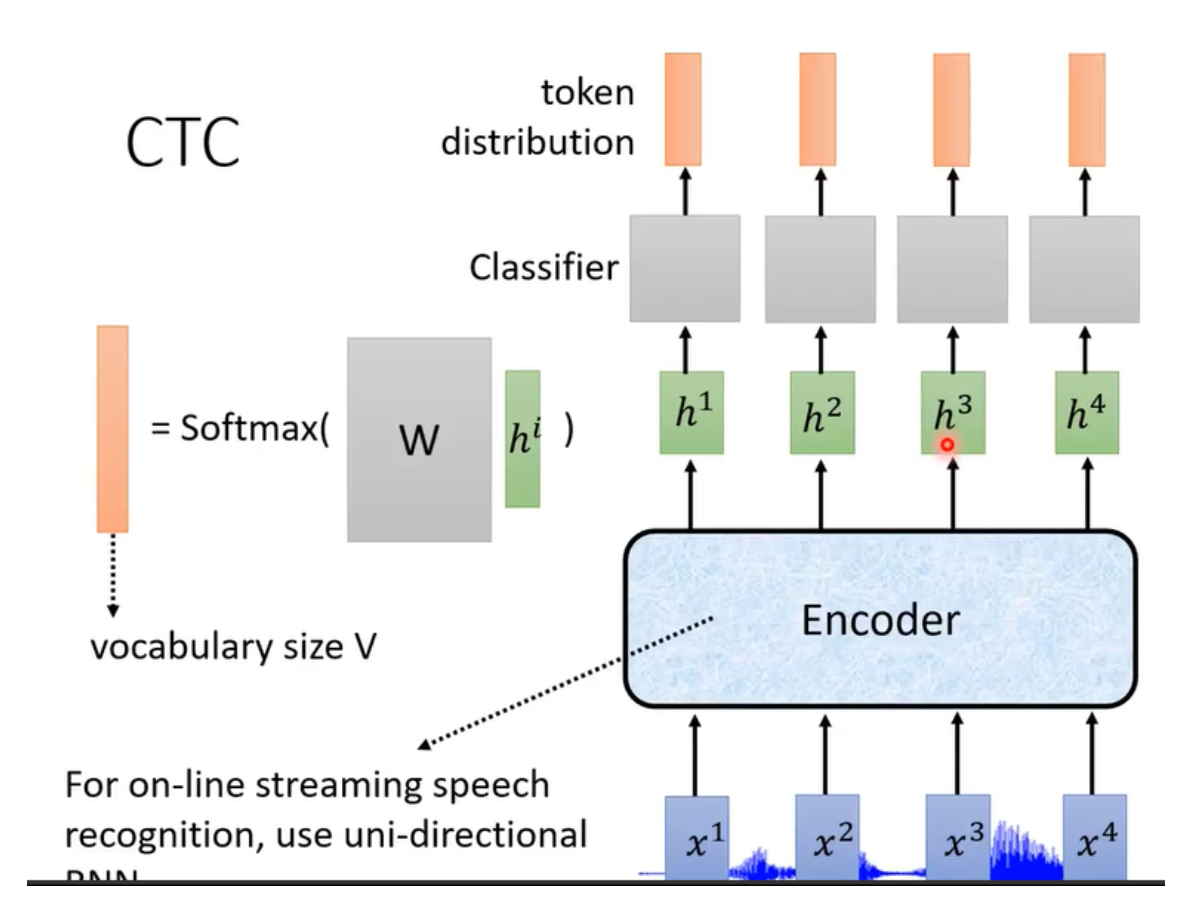
CTC
CTC可以做到一边听一边辨识,只需要encoder把 \(h\) 输出,通过一个线性分类器,
在CTC中加入了一个特别的token,用 \(\emptyset\) 表示,这是为了对齐语音和文本。在两个 \(\emptyset\) 中间重复的token合并,并去除 \(\emptyset\)。
训练时,穷举所有可能性。
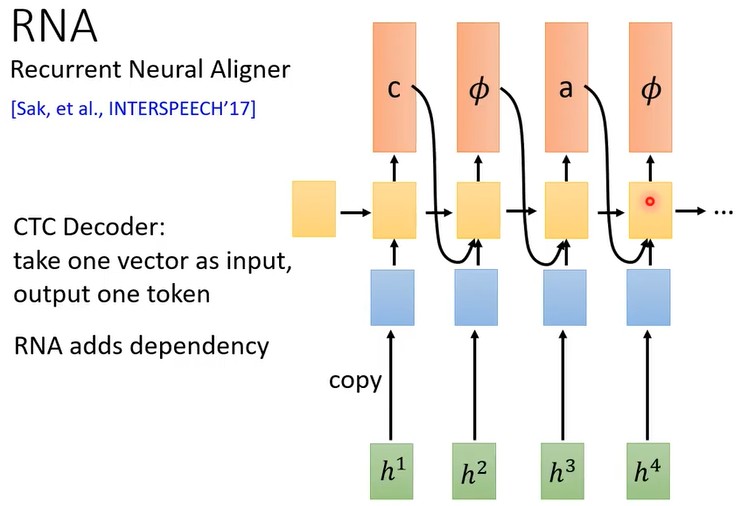
RNA
CTC 的 decoder看不到前面的信息,因此把linear classifier换成RNN或者LSTM。
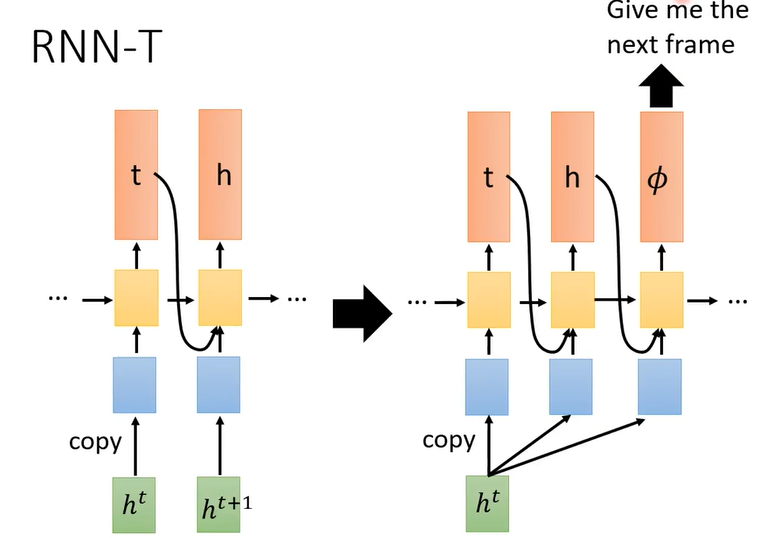
RNN-T
吃一个输入,输出多个token
看到一个输入之后就一直输出,直到输出到模型觉得满意为止(输出 \(\emptyset\))
Whisper:弱监督方法。将数据集从4h做到了68h。模型仅仅是Transformer模型。
语音基础知识
http://example.com/2025/01/19/语音基础知识/